在 Search Query III 這一篇內有提到可以用 bool query 結合兩個 query,knn 是可以被放在 bool query 內被一起使用的。
GET tmdb_top_rated_movies_e5_small/_search?
{
"query": {
"bool": {
"should": [
{
"match": {
"overview": {
"query": "黑道",
"_name": "text"
}
}
},
{
"knn": {
"field": "overview_vector",
"query_vector": [<the vector>],
"k": 10,
"_name": "knn"
}
}
]
}
},
"_source": false,
"fields": [
"title"
]
}
在 full-text query 和 knn query 內都有一個欄位是 _name ,這個欄位的功能是替搜尋命名,在搜尋結果就可以看到這筆資料是因為哪一個 query 而被挑出來的,如下的 matched_queires 欄位:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 148,
"relation": "eq"
},
"max_score": 6.2798615,
"hits": [
{
"_index": "tmdb_top_rated_movies_e5_small",
"_id": "1422",
"_score": 6.2798615,
"fields": {
"title": [
"神鬼無間"
]
},
"matched_queries": [
"knn",
"text"
]
},
...
]
}
}
這樣確實結合了兩種 query,但其中有一個細節市值得注意的:排序。
這兩種搜尋在計分的方式上差異是很大的: full text search 和 KNN on Vector Search 都會在 search result 中根據 score 排序,在 KNN 的 score 主要是 vector 的 similarity 決定,而在 full-text search 則是 tf-idf 決定。bool_match 會純粹以分數來排序,因此若沒有做任何調整,在大部分狀況下,full-text query 找到的資料排序都會在比較前面(分數比較高),只有少數狀況如搜尋關鍵字沒有出現在資料裡的時候,KNN 的結果才會跳出來。
就算是經過調整(例如設定 boost),在概念上這兩種計分方式得到的數值是真的可以被比較的嗎?
ES 有考量到這個情境,所以提供了 Reciprocal rank fusion (RRF) 的 search 可以使用。
依照官網,RRF 的算法是這樣的:
score = 0.0
for q in queries:
if d in result(q):
score += 1.0 / ( k + rank( result(q), d ) )
return score
# where
# k is a ranking constant
# q is a query in the set of queries
# d is a document in the result set of q
# result(q) is the result set of q
# rank( result(q), d ) is d's rank within the result(q) starting from 1
上面的計算過程會針對每一筆資料進行,使用實例來說明:
以下表格是針對 6 筆資料使用 KNN search 和 full-text search 的 rank 和 score
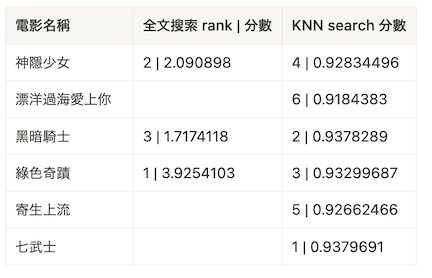
假設 k 是 10。
如果以神隱少女為例,就會是 1 / ( 10 + 2 ) + 1 / ( 10 + 4) = 0.1548
全部算完之後就會再根據這個分數排序一次。
不過這個功能,只有企業版有,所以就沒有辦法 demo 了;我們下一篇見。

